
seq2seq & attention
问题
大多数attention都是时域attention,即关注输入序列(或者encoder的输出序列)中各个timestep的数据的不同贡献
那么频域attention该怎么做呢?比如要关注图像的某一部分对分类器的贡献?
最普通的,例如一个MLP1 + Attention + MLP2的结构,MLP的输出shape为(batch_size,hidden_dim),即timestep为1,怎么算attention?
timestep为1的时候,softmax->sigmoid,概率分布不存在了,按原算法得到的attention是一个shape为(batch_size,1,1)的张量乘上encoder_output,相当于对每个feature乘上一个实数,意义是什么?
Update 2021-02-18: 参考这里。
把握住attention的本质是加权,由此,
卷积网络里有两种attention,一种是通道attention,对各个feature map加权;一种是空间attention,利用卷积运算获得spatial attention。
PyTorch Misc
LSTM的返回值
1 | output(seq_len, batch, hidden_size * num_directions) # 每个timestep,最后(深)一层的神经元输出的拼接 |
inplace=True
激活函数例如nn.LeakyReLU(inplace=True)中inplace=True的意思是进行原地操作,例如x=x+5,对于Conv2d这样的上层网络传递下来的tensor直接进行修改,好处就是可以节省运算内存。
dim=-1
dim=-1意为对最后一维进行操作
permute(dims)
将tensor的维度换位
permute(0,2,1) -> 将后两维对换
torch.cat(tensors, dim)
按dim拼接tensors
torch.chunk(tensor, chunk_num, dim)
与torch.cat()原理相反,它是将tensor按dim(行或列)分割成chunk_num个tensor块,返回的是一个元组。
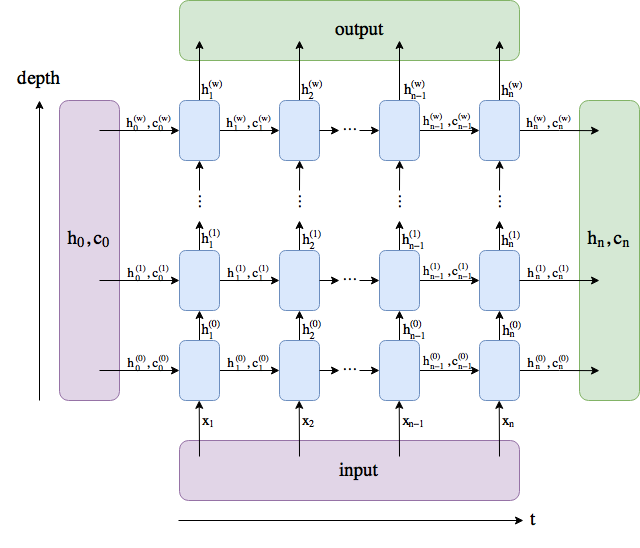
LSTM原理
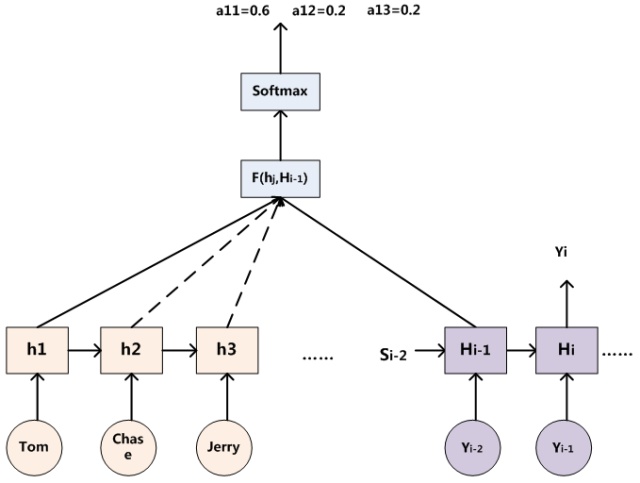
Attention原理
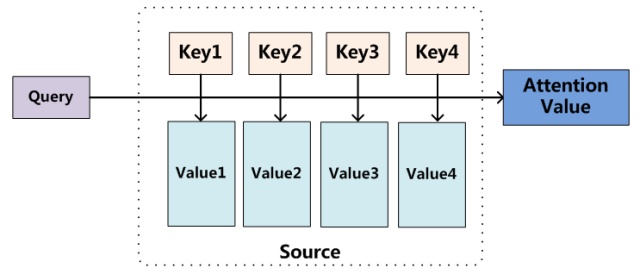
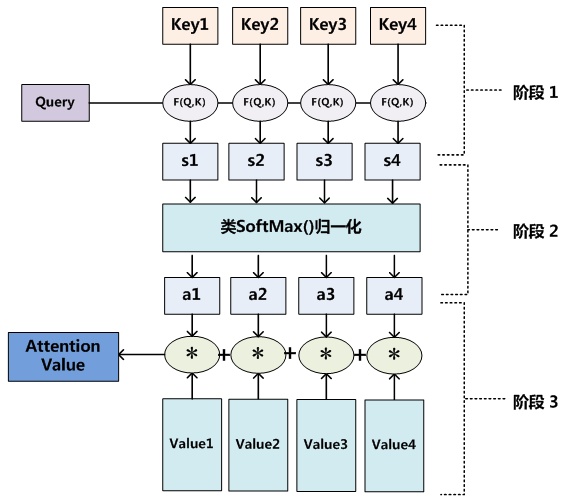
Attention详解
seq2seq pipeline: input vector -> encoder -> context vector -> decoder -> output vector
一般的attention公式
1 | M = tanh(lstm_output) |
att_weight 是一个(1, hidden_dim)的向量
对应attention本质模型,key=value=lstm_ouput,query向量在哪呢? – 在att_weights中
query是学习出来的,不然attention就成了先验知识了
在这里看到:把att_weight用MLP(lstm_hidden_state)代替(因为decoder的隐藏层输出和encoder的隐藏层输出处在同一个子空间内),更有道理一些,不知道效果怎么样
要计算query和key的相似度,可以通过內积的方式表征,更一般的,可以写作F(query,key),怎么定义随便,F甚至可以是NN;进一步推广,将query嵌入NN中,直接NN(lstm_output)即为相似度
算完相似度之后,用softmax计算归一化的概率分布,再乘上value即可。
自注意力机制即K=V=Q,即为query=G(value) <==> att_weights = G(lstm_outputs), G为任意变换,比如NN
Transformer
Attention is all you need
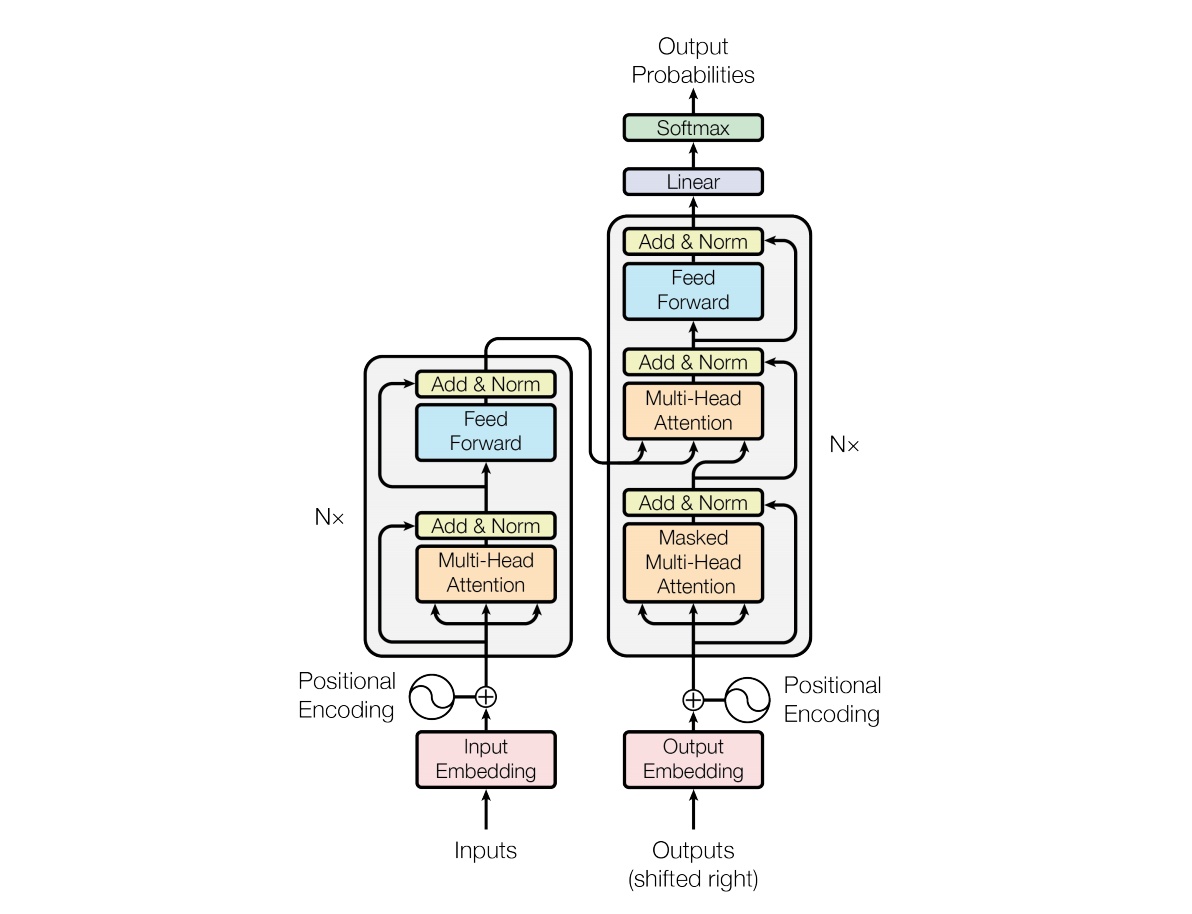
提出Transformer架构
encoder部分,输入数据经过Embedding之后,直接接多头自注意力层,不再先经过特征提取层例如CNN或者LSTM,然后再接一个MLP变换 +
残差,送入decoder
Transformer为每个输入单词的词嵌入上添加了一个新向量——位置向量,即embedding_with_time_signal =
positional_encoding + embedding
多头attention(Multi-head attention)
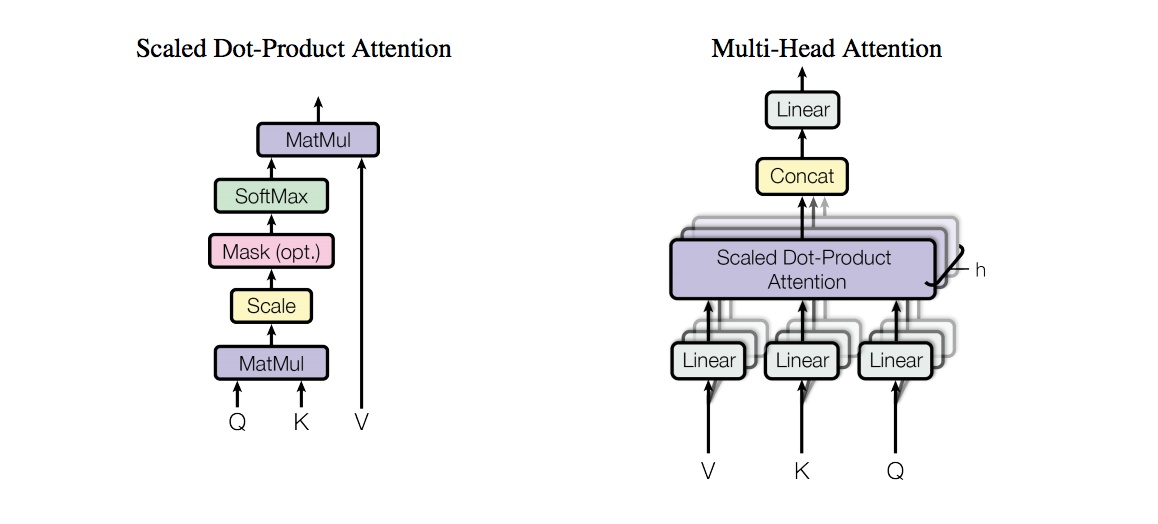
结构如图,Query,Key,Value首先进过一个线性变换,然后输入到放缩点积attention
注意这里要做h次,也就是所谓的多头,每一次算一个头,头之间参数不共享,每次Q,K,V进行线性变换的参数是不一样的。
然后将h次的放缩点积attention结果进行拼接,再进行一次线性变换得到的值作为多头attention的结果。
论文中说到这样的好处是可以允许模型在不同的表示子空间里学习到相关的信息。
代码实现上,即将Query/Key/Value都reshape一下
(batch_sze, timesteps, hidden_dims) -> (batch_sze*num_heads, timesteps, hidden_dims/num_heads)
1 | class MultiHeadAttention(nn.Module): |